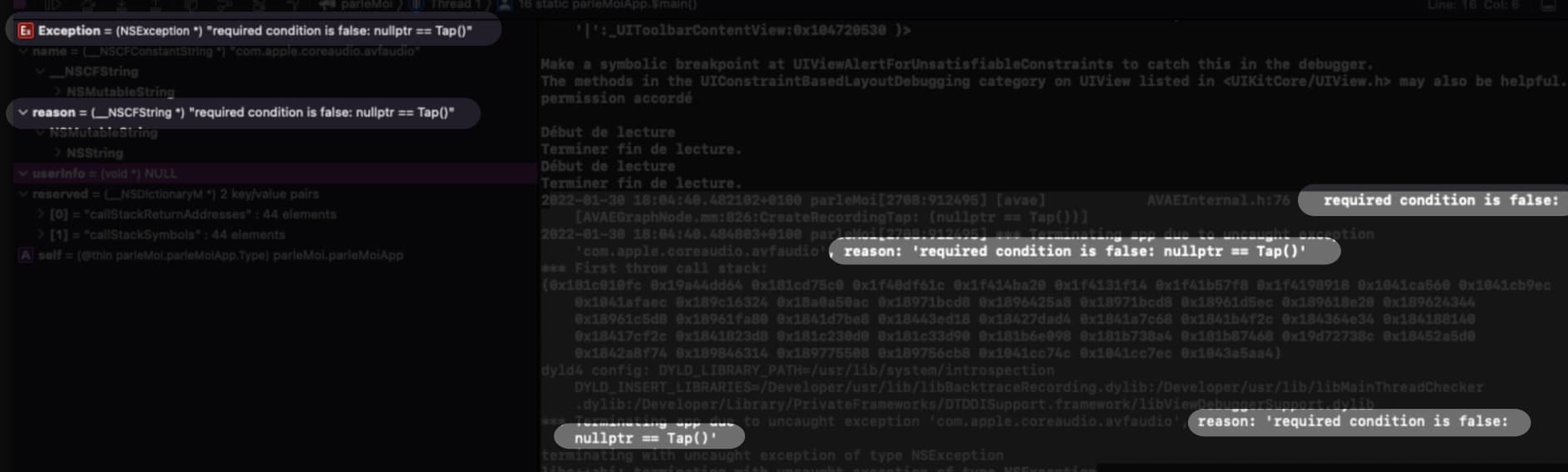
Bonjour j’essaie de créer un exemple avec swiftUI avec les frameworks SFSpeechRecognizer et AVSpeechSynthesizer mon exemple fonctionne sur le simulateur, mais pas sur un iPhone.
J’arrive bien à faire plusieurs enregistrements de ma voix à la suite les uns des autres, idem pour la lecture. L’application crache si je veux refaire un enregistrement après avoir fait une lecture.
je ne sais pas interpréter le message erreur de la console
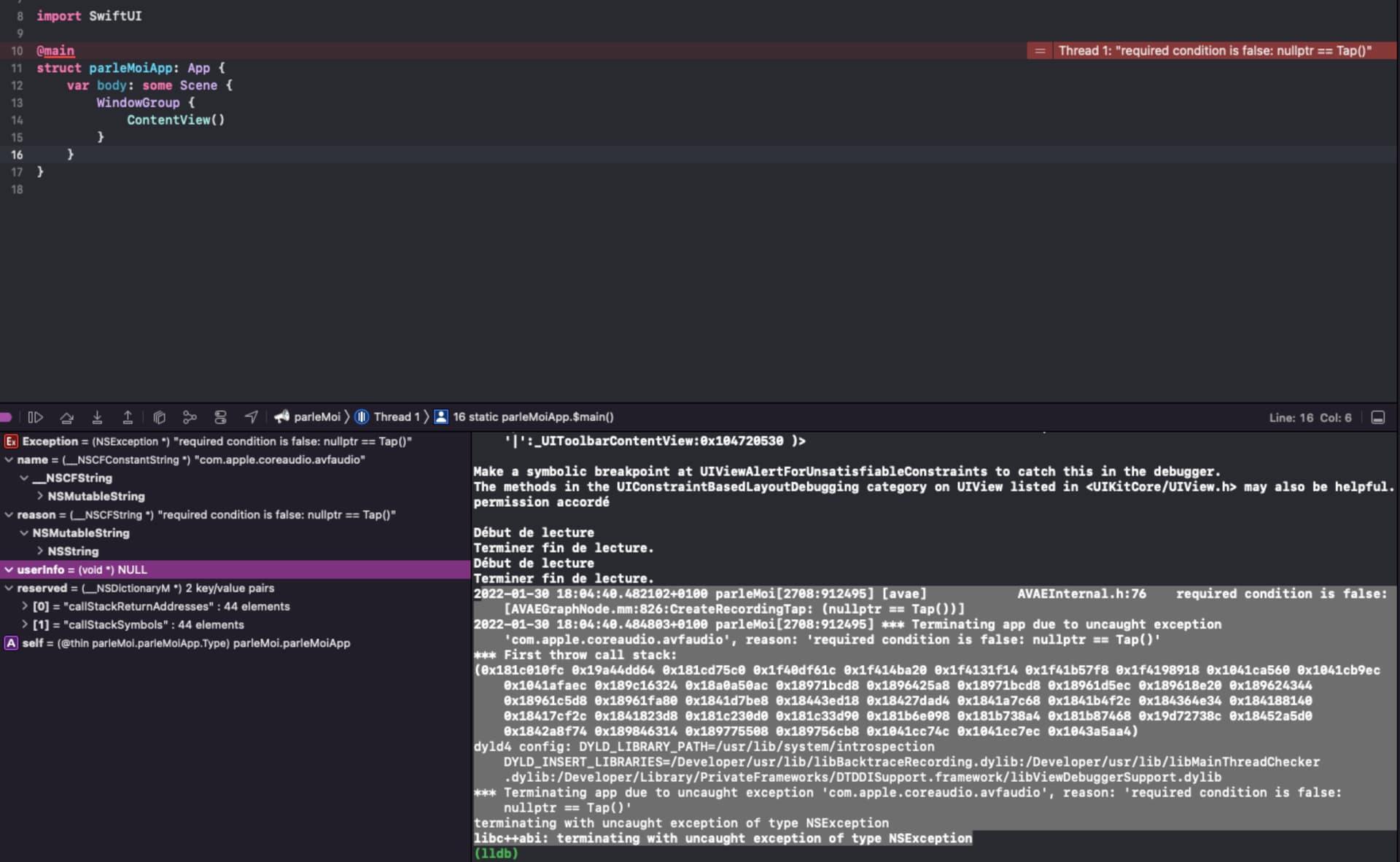
il me manque des choses dans mon code ?
import Speech
import AVFoundation
class ReconnaissanceVocaleViewModel:NSObject, ObservableObject, SFSpeechRecognizerDelegate {
// création du manageur + configuration de la langue
//var speechRecognizer:SFSpeechRecognizer? = SFSpeechRecognizer(locale: Locale(identifier: "fr-FR"))
// création du manageur + configuration de la langue
var speechRecognizer:SFSpeechRecognizer? = SFSpeechRecognizer(locale: Locale(identifier: Locale.current.identifier))
// Gestion du partage voix
let audioSession = AVAudioSession.sharedInstance()
// moteur
let engine = AVAudioEngine()
// requete
var request: SFSpeechAudioBufferRecognitionRequest?
// tache de transcription de la voix en texte
var task: SFSpeechRecognitionTask?
@Published var enregistrementEnCours:Bool = false
@Published var transformerVoixText:String?
@Published var boutonUtilisationMicro:Bool = false
override init() {
super.init()
speechRecognizer?.delegate = self
// autorisation utilisation micro
SFSpeechRecognizer.requestAuthorization { (autorisationMicro) in
OperationQueue.main.addOperation { [self] in
switch autorisationMicro {
case .authorized:
print("permission accordé")
boutonUtilisationMicro = true
case .notDetermined:
print("aucune réponse")
case .denied:
print("aucune permission accordé")
boutonUtilisationMicro = false
case .restricted:
print("seulement si l'application est active")
boutonUtilisationMicro = true
default:
print("réponse par défault")
}
}
}
}
// demarre la transcription de la voix en texte
func demarrerTranscriptionVoix() {
//supprime les transcription precédentes
enregistrementEnCours = true
if task != nil {
task?.cancel()
task = nil
}
//Préparer l'enregistrement
// Le nœud audio pour l'entrée singleton du moteur audio. (doc apple)
let node = engine.inputNode
//configuration de la session
do {
try audioSession.setCategory(.record, mode: .measurement, options: .mixWithOthers)
try audioSession.setActive(true, options: .notifyOthersOnDeactivation)
request = SFSpeechAudioBufferRecognitionRequest()
guard request != nil else { return }
task = speechRecognizer?.recognitionTask(with: request!, resultHandler: { (resultat, erreur) in
//Erreur ou resultat final
if erreur != nil || (resultat != nil && resultat!.isFinal) {
//Arrête
print(erreur?.localizedDescription ?? "")
// arret du moteur, arret du processus
self.engine.stop()
// suppression bus enregistrement
node.removeTap(onBus: 0)
self.request = nil
self.task = nil
}
if resultat != nil {
self.transformerVoixText = resultat!.bestTranscription.formattedString
//print(self.transformerVoixText) // affiche texte dans la console
}
})
let format = node.outputFormat(forBus: 0)
node.installTap(onBus: 0, bufferSize: 1024, format: format) { (buffer, time) in
self.request?.append(buffer)
}
engine.prepare()
do {
try engine.start()
} catch {
print("Erreur au lancement => \(error.localizedDescription)")
}
} catch {
print("Erreur du set de catégory => \(error.localizedDescription)")
}
}
// arret de la retranscrpition de la voix
func arretTranscription() {
do {
engine.stop()
request?.endAudio()
try audioSession.setActive(false, options: .notifyOthersOnDeactivation)
enregistrementEnCours = false
} catch {
print(error.localizedDescription)
}
}
import AVFAudio
import AVFoundation
class SyntheseVocaleViewModel:NSObject, ObservableObject, AVSpeechSynthesizerDelegate {
var speechSynthesizer:AVSpeechSynthesizer = AVSpeechSynthesizer()
// variable de partage du canal audio
var audioSession = AVAudioSession.sharedInstance()
// vitesse de lecture
var rate:Float = AVSpeechUtteranceDefaultSpeechRate
var volume:Float = 0.5
// configuration type de langue
var voice = AVSpeechSynthesisVoice(identifier: Locale.current.identifier)
// variable etat de la lecture
@Published var lectureEnCours:Bool = false
override init() {
super.init()
self.speechSynthesizer.delegate = self
}
// volume Audio
func volumeAudio(niveauVolume:CGFloat) {
volume = Float(niveauVolume)
}
// definir la vitesse de lecture
func rythmeLecture(vitesseLecture:CGFloat) {
rate = Float(vitesseLecture)
}
// lecture du texte
func demarrerLecture(texte:String) {
// gestion du mode lecture
// gestion de partage du canal de son entre plusieurs application.
do {
// configuration du type de flux audio
try audioSession.setCategory(.playAndRecord, mode: .spokenAudio, options: .defaultToSpeaker)
// demande l'utilisattion du canal audio
try audioSession.setActive(true, options: .notifyOthersOnDeactivation)
// utterance (contient le texte à lire.
let utterance = AVSpeechUtterance(string: texte)
utterance.voice = voice
//utterance.volume = volume
utterance.rate = rate
speechSynthesizer.speak(utterance)
} catch let error as NSError {
print("type erreur \(error.localizedDescription)")
}
}
// arrete la lecture
func arretLecture() {
// arret de la lecture après le dernier mot en cours
speechSynthesizer.stopSpeaking(at: .word)
}
func speechSynthesizer(_ synthesizer: AVSpeechSynthesizer, didStart utterance: AVSpeechUtterance) {
print("Début de lecture")
self.lectureEnCours = true
}
func speechSynthesizer(_ synthesizer: AVSpeechSynthesizer, didPause utterance: AVSpeechUtterance) {
// non utilisé pour l'exemple
}
func speechSynthesizer(_ synthesizer: AVSpeechSynthesizer, didContinue utterance: AVSpeechUtterance) {
// non utilisé pour l'exemple
}
func speechSynthesizer(_ synthesizer: AVSpeechSynthesizer, didCancel utterance: AVSpeechUtterance) {
// non utilisé pour l'exemple
}
func speechSynthesizer(_ synthesizer: AVSpeechSynthesizer, willSpeakRangeOfSpeechString characterRange: NSRange, utterance: AVSpeechUtterance) {
// non utilisé pour l'exemple
}
func speechSynthesizer(_ synthesizer: AVSpeechSynthesizer, didFinish utterance: AVSpeechUtterance) {
do {
// rend le flux audio disponible pour les autre application
try self.audioSession.setActive(false, options: .notifyOthersOnDeactivation)
print("Terminer fin de lecture.")
self.lectureEnCours = false
} catch let error as NSError {
print("type erreur \(error.localizedDescription)")
}
}
}
pour mieux comprendre
une vidéo exemple https://youtu.be/CHJwLVca0rU
L’exemple complet sur code GitHub
Merci de votre aide.